How to get git config username and email
By Emily
When connecting to a repo for the first time you will need to provide git ...
Read moreBy Emily
When connecting to a repo for the first time you will need to provide git ...
Read more
By Emily
Let’s face it we all find it hard to commit sometimes. But that would be ...
Read moreBy Emily
If you’ve just realised you’re working on the wrong branch and you’ve already made changes, ...
Read moreBy Emily
If you’ve worked with git repos for a while you will no doubt have come ...
Read more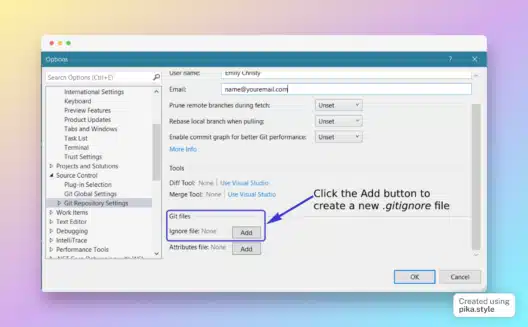
By Emily
If you’ve just started a project and created a new solution in Visual Studio 2022 ...
Read moreBy Emily
If you see the “fatal: No such remote ‘origin’” message then you are probably trying ...
Read more
By Emily
Following on from my previous post which explains how to get your git config username ...
Read moreBy Emily
Git tags are one of those topics I’ve heard people discuss but I hadn’t had ...
Read moreBy Emily
It’s happened to me many times – I do loads of coding on a feature ...
Read more